Groq LPU 內部構造大解密:揭開專為 LLM 推論打造的「可程式化輸送帶」語言處理核心
想像一下:當傳統 GPU 在大型語言模型(如 Llama 3 8B)面前被記憶體頻寬和數據移動瓶頸卡住時,Groq 的 LPU(Language Processing Unit)卻像一條精密的 AI 組裝線,以「確定性」和「片上 SRAM 主導」的革命性設計,徹底翻轉遊戲規則。根據 Groq 最新技術分享,這項突破讓 Llama 3 8B 模型的記憶體使用量減少至原本的六分之一,同時大幅提升推論速度。這不僅來自硬體創新,更仰賴軟硬體協同優化——其中包括他們開發的「Dynamic Sparse Attention」技術,能動態捕捉注意力機制中的稀疏模式,減少無謂計算與存取。
今天,我們就來「想像」並深入剖析 Groq LPU 的內部構造。這不是純粹的虛構,而是基於 Groq 公開的 Tensor Streaming Processor(TSP)架構、SRAM 設計與編譯器優化原理,結合官方圖示與概念視覺化,為您呈現一篇詳盡的圖文專文。讓我們一步步走進這顆晶片的「心臟」。
1. LPU 核心理念:單核心 + 海量片上 SRAM,告別 DRAM 瓶頸
傳統 GPU 依賴外部 DRAM/HBM 作為主要權重儲存,數據來回搬運造成巨大延遲與功耗。Groq LPU 則從設計之初就顛覆這一點——它完全沒有外部 DRAM,而是將數百 MB(最新 Groq 3 LPU 達 500 MB)的高速 SRAM 作為「主要權重儲存」(而非僅作為快取)。
這種「扁平記憶體階層」讓計算單元能以全速直接拉取權重,延遲大幅降低。想像晶片內部就像一座高速工廠,所有關鍵數據(模型權重、激活值、KV 快取)都緊鄰生產線,編譯器事先精準安排好每一步「物料搬運」。

(上圖:Groq LPU 與 GPU 記憶體對比。左側 GPU 使用 288 GB HBM4,右側 LPU 僅用 500 MB SRAM 卻達到 150 TB/s 超高頻寬,展現「少而精」的極致效率。)
2. 功能單元解構:MXM、VXM、SXM、MEM 的「流水線部隊」
LPU 的內部採用「Tensor Streaming Processor」架構,像一條垂直與水平交織的組裝線。晶片被切割成多個功能切片(slices),數據以 320 位元組向量為單位,在東-西方向(左右)流動,指令則從北向南(上下)傳播,形成高度可預測的管線執行。
主要功能單元包括:
- MXM(Matrix Multiply Unit):專責密集矩陣乘法,是 Transformer Attention 與 FFN 的主力「重砲」。
- VXM(Vector Execution Module):處理點對點運算、激活函數、類型轉換等向量操作。
- SXM(Switch / Spatial Execution Module):負責數據移動、置換、旋轉、轉置等,支援動態重排。
- MEM(Memory Unit):海量 SRAM 塊,提供 150 TB/s 級別的極致頻寬,直接作為工作儲存。
這些單元排列成「條紋式」(striped)布局,數據像傳送帶一樣在相鄰單元間傳遞,編譯器在編譯階段就已完全排程好每一步,避免運行時衝突。

(上圖:NVIDIA Groq 3 LPU 晶片架構詳細區塊圖。清楚顯示 MXM、SXM、MEM、VXM 的垂直堆疊,以及 C2C(Chip-to-Chip)互聯與高頻寬 SRAM 配置。這正是 LPU「Tensor-First Compute」的視覺化呈現。)
想像內部運作:當 Llama 3 的 Attention 層啟動時,MXM 高速計算 QKV 矩陣乘法,SXM 同步進行置換,MEM 則即時供應權重——整個過程確定性極高,無需複雜的硬體快取管理。
3. Dynamic Sparse Attention 與編譯器魔力:記憶體使用量暴減 6 倍的關鍵
Groq 的突破不僅在硬體,更在軟體堆疊。Dynamic Sparse Attention 技術能即時識別注意力矩陣中的稀疏模式,只計算真正重要的權重,跳過近乎零的元素。這大幅減少中間結果的記憶體占用與計算量。
搭配先進編譯器:
- 靜態排程(Static Scheduling):一切在編譯時決定,無運行時不可預測性。
- 圖層融合與動態記憶體重用:多層操作融合為單一核,記憶體空間在層間循環利用。
- 針對 Llama 3 的客製優化:精準映射模型結構到 LPU 的 320B 向量流,實現權重與激活的高效壓縮。
結果?Llama 3 8B 原需龐大記憶體,現在只需六分之一,就能跑在更小、更省電的硬體上,推論速度同步飛躍。
為什麼靜態排程如此關鍵?(用輸送帶比喻來說明)
想像傳統 GPU 像一座忙碌的工廠:
- 有很多工人(運算單元)
- 但物料(資料)要靠臨時排班、動態搶資源、等待緩衝區
- 有時候塞車、有時候空轉,時快時慢,無法保證每批貨物什麼時候準時到達下一站
而 Groq LPU 則像一條高度精密的自動化輸送帶工廠(programmable assembly line):
- 在編譯階段(compile time),Groq Compiler 就已經把整個 LLM 模型拆解成每一個運算步驟、每一筆資料的移動路徑
- 它精確計算:這個向量運算需要剛好多少個時脈週期(clock cycle)、資料何時必須出現在哪一個功能單元
- 所有資料就像被預先設定好節奏的零件,在輸送帶上穩定流動
- 運行時(runtime)完全不需要硬體做動態排程、仲裁或猜測,沒有 cache miss、沒有分支預測失敗、沒有運行時等待
結果就是確定性執行(Deterministic Execution): 同一個模型、同一個輸入,每次產生 token 的時間都幾乎一模一樣,毫無抖動(jitter)。這對即時對話、串流生成極為重要。
這帶來的好處(與 GPU 對比)
- 可預測的低延遲:編譯器說 28.5 毫秒就是 28.5 毫秒,不會因為系統負載突然變慢
- 消除 Memory Wall:大量運算與資料移動都在編譯時就安排好,搭配片上巨量 SRAM,資料幾乎不會「等記憶體」
- 線性擴展:多顆 LPU 串聯時,行為仍然像一條更長的輸送帶,而不是一群需要互相協調的混亂工人
這也是 Groq 一直強調的 Software-First 設計哲學:把智慧放在 Compiler,而不是讓硬體在運行時自己想辦法。
4. 晶片間擴展:Tensor Parallelism 與軟體排程網路
單顆 LPU 已是強悍,但 Groq 真正強大之處在於多晶片無縫擴展。透過 C2C(Chip-to-Chip)互聯(最新版高達 96 條連結、112 Gbps/連結),多顆 LPU 可像單一巨型核心般運作,支援 Tensor Parallelism——將單一模型層切割到多顆晶片,加速單次前向傳遞。

(上圖:Groq 3 LPX Compute Tray 實體布局。8 顆 LPU 緊密排列,搭配光學互聯與液冷設計,展現從單晶片到機架級的擴展能力。)
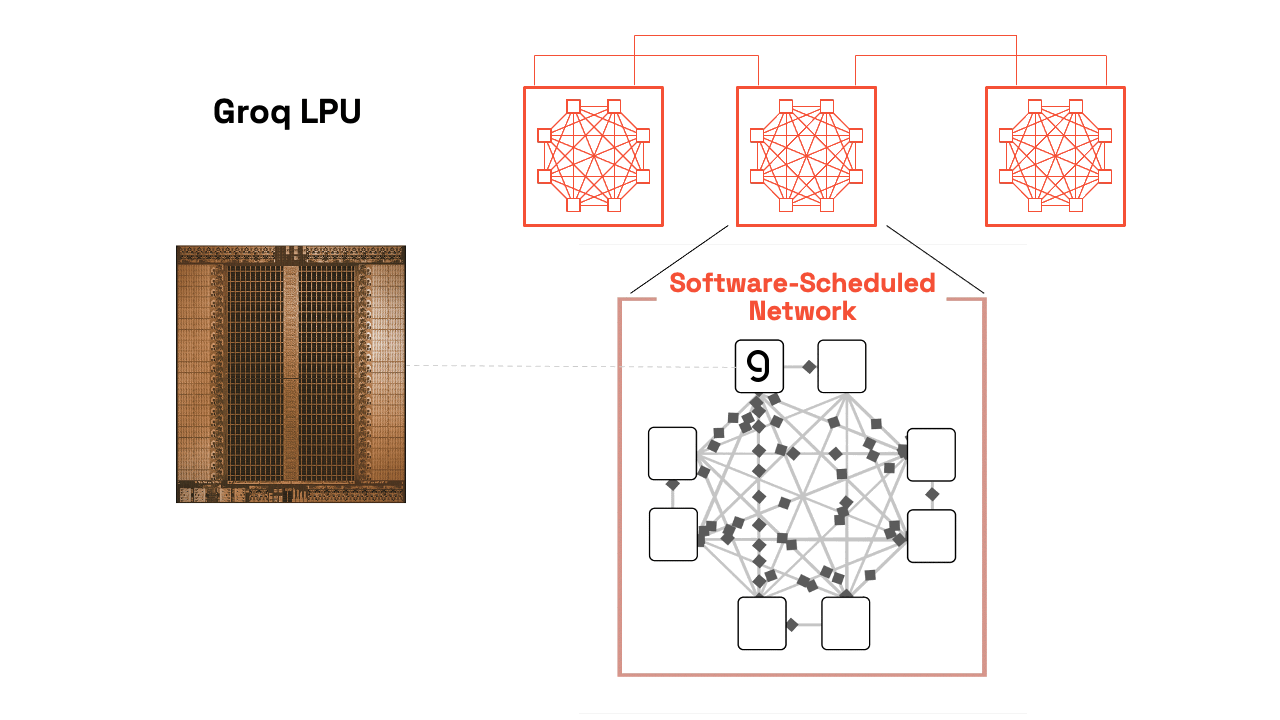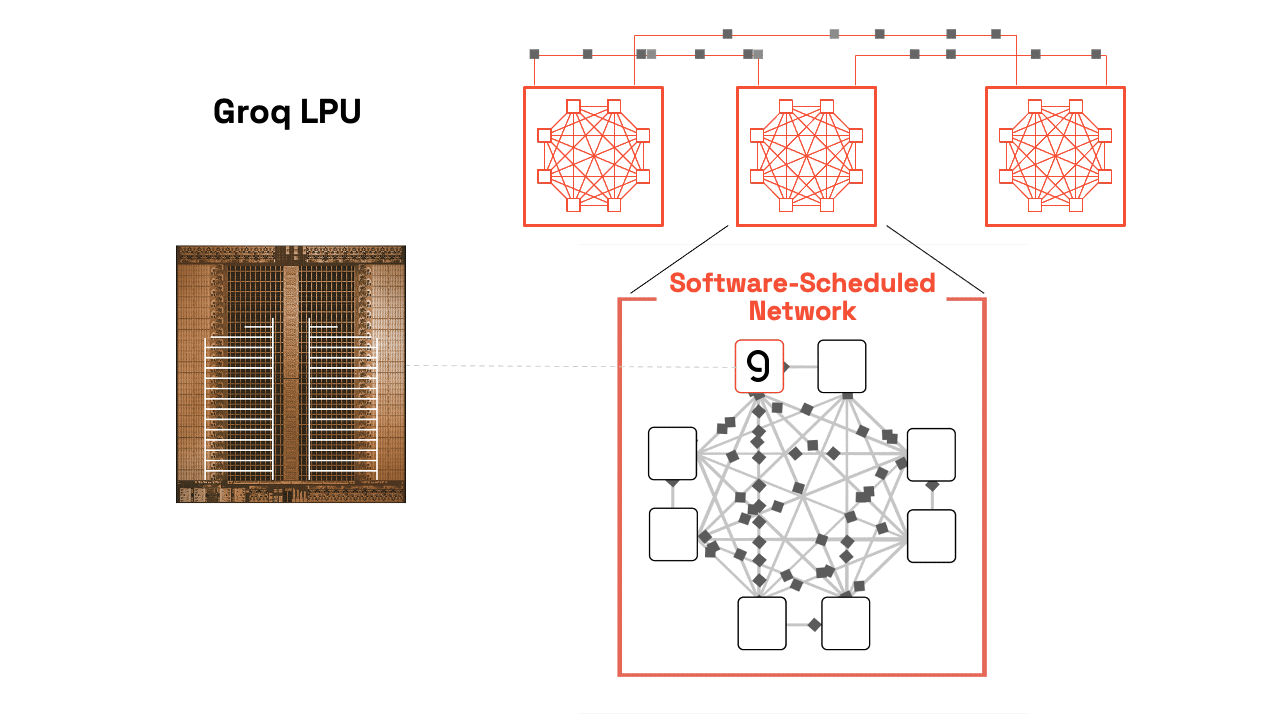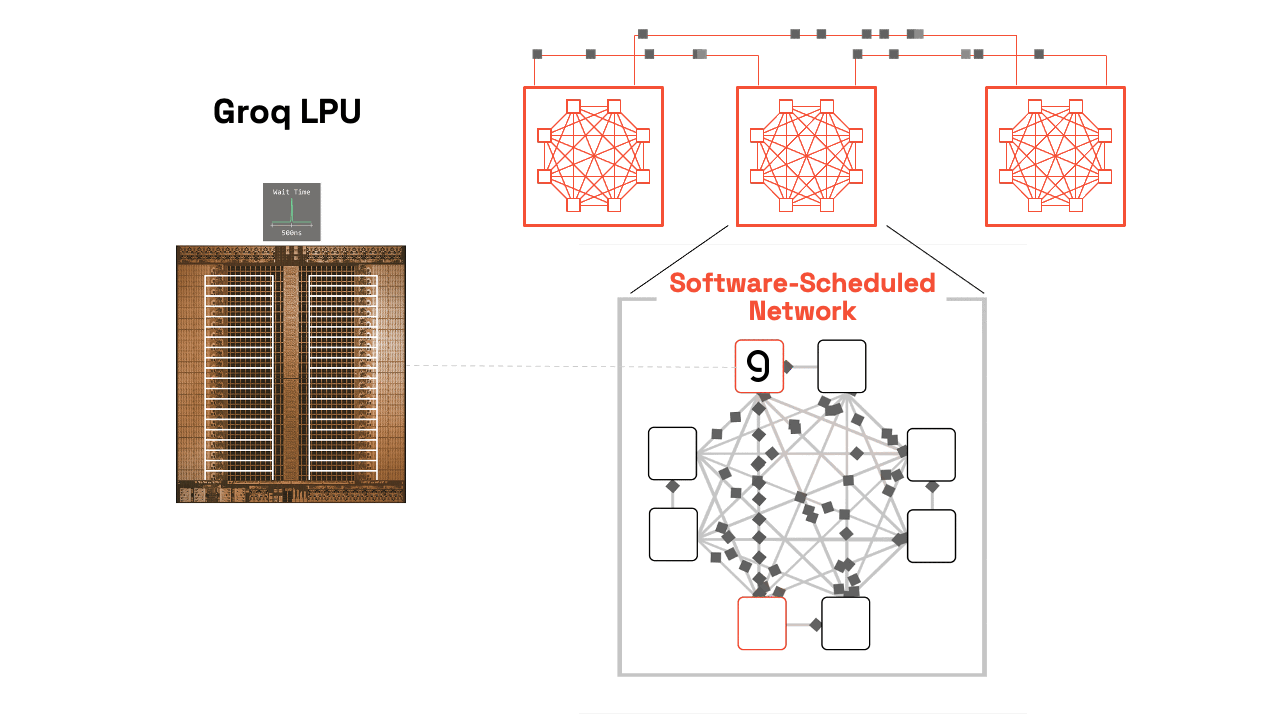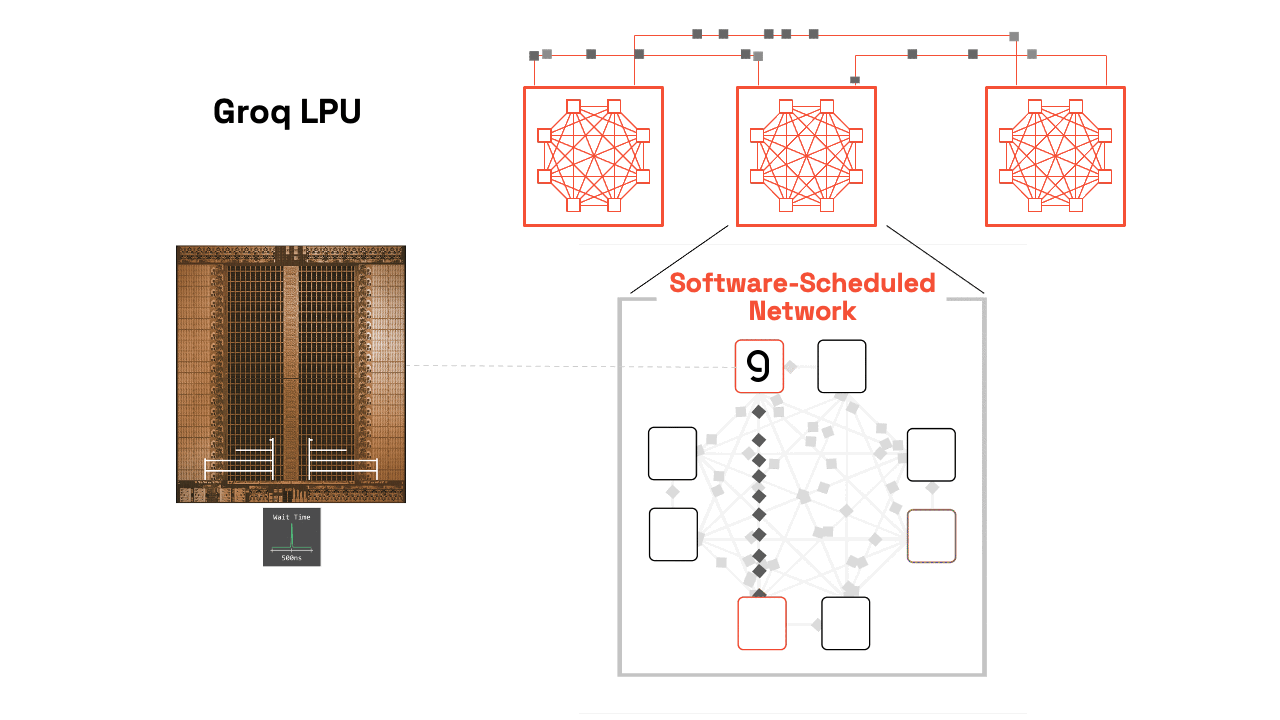
(上圖:Groq LPU 系統層級視圖,從 GroqChip™ 到 GroqRack™,軟體排程網路讓數百顆 LPU 同步如一。)
5. 想像中的「內部構造」3D 視覺化
如果我們進一步想像 LPU 內部剖面:晶片中央是一片片閃爍的 SRAM 海洋(MEM),周圍環繞著矩陣乘法引擎(MXM)如工廠主機台,向量單元(VXM)則像靈活的機械臂,SXM 負責「轉運帶」切換。數據流以固定向量形式高速穿梭,編譯器事先畫好每條路徑——整個過程安靜、確定、可預測,像一台永不卡頓的 AI 超級跑車。
(以下為 Grok Imagine 生成的概念圖,幫助您更直觀感受這份想像。)


結語:這項技術的深遠意義
Groq LPU 最直接的競爭將聚焦於 AI 推論市場。NVIDIA 的 GPU 因其通用性、大規模並行計算能力和成熟的生態系統,在 AI 模型的訓練領域仍將保持主導地位。然而,對於特定工作負載,特別是大型語言模型(LLM)的推論,Groq 等專用加速器有望憑藉其卓越的速度和效率,從 GPU 手中奪取一部分市場份額。
這將促使市場走向分化:GPU 繼續稱霸訓練,而專用加速器則在推論領域,尤其是在追求極致即時性和效率的 LLM 應用中,嶄露頭角。NVIDIA 當然會透過軟體優化(如 TensorRT)和新一代 GPU 架構來應對,但專用晶片的興起無疑會加劇競爭,推動整個產業提升效能和效率。
2. 對 HBM(高頻寬記憶體)的影響:需求趨緩還是轉型?
HBM 因其極高的頻寬,是當前高階 AI GPU(如 NVIDIA 的 H100/H200)不可或缺的記憶體解決方案。它主要用於滿足大型模型訓練和推論中對海量參數的快速存取需求。
Groq LPU 的設計策略是透過大量的片上 SRAM 來避免對外部 DRAM(包括 HBM)的依賴。如果 Groq 這類架構被廣泛採用,那麼在推論領域,對 HBM 的需求增長可能會受到一定程度的抑制。因為專用加速器可能不再需要像 GPU 那樣依賴外部 HBM 來儲存模型權重和激活值。
然而,HBM 在 AI 模型訓練領域的重要性仍然無可替代。訓練通常涉及更大規模的數據和模型權重,對頻寬的需求遠超推論。因此,儘管推論市場可能部分轉向片上記憶體方案,HBM 的整體市場需求仍將因 AI 訓練的持續增長而保持強勁。HBM 技術本身也在不斷演進(HBM3E、HBM4),將繼續在需要極高頻寬的計算領域扮演關鍵角色。
3. 對台積電 CoWoS 先進封裝的影響:持續的關鍵地位
CoWoS(Chip-on-Wafer-on-Substrate)是台積電領先的 2.5D/3D 先進封裝技術,對於整合 GPU 與 HBM 晶片,提供極高互連密度和頻寬至關重要。無論是 NVIDIA 的高階 GPU、Google 的 TPU,還是未來 Groq 更複雜的下一代 LPU,如果需要整合多個邏輯晶片或搭配其他輔助晶片(即使不是 HBM),CoWoS 這類先進封裝技術都可能是不可或缺的。
Groq LPU 目前雖然不依賴 HBM,但如果未來為了追求更高的效能,需要將多個 LPU 核心整合在一個封裝中(多晶粒模組),或者與其他類型的記憶體/I/O 晶片整合,CoWoS 仍將是理想的解決方案。
總之,隨著 AI 晶片複雜度的不斷提高,對 CoWoS 這種先進封裝技術的需求只會增長。台積電在這一領域的領先地位,即使在 AI 硬體生態系統不斷演進的過程中,也將持續扮演關鍵角色。
未來展望:多元與協作的 AI 硬體生態
Groq 的創新代表了 AI 硬體發展的一個重要趨勢:針對特定工作負載進行深度優化和軟硬體協同設計。 這項技術的普及將帶來多方面的影響:
降低 LLM 部署門檻: 更低的硬體成本和運行費用,將使更多的企業和開發者能夠部署和應用大型語言模型,加速 AI 應用創新。
推動實時 AI 應用: 極致的推論速度將使得實時對話、即時內容生成等 AI 應用變得更加流暢和普及。
拓展邊緣 AI: 更低的記憶體和功耗需求,使得 LLM 在邊緣設備上運行的可能性大大增加,開啟 AI 服務的新場景。
綠色 AI: 提升能源效率有助於減少 AI 的碳足跡,符合可持續發展的趨勢。
Groq 的技術無疑為 AI 硬體市場帶來了新的活力和競爭。它可能不會完全取代 GPU 或 HBM,但會促使整個產業鏈更加精進,發展出更豐富、更多元且更高效的 AI 硬體解決方案。
Groq LPU 的內部構造,不僅解決了傳統架構的記憶體瓶頸,更開啟了 LLM 部署的新紀元。更少的記憶體意味著能在邊緣設備、更小型伺服器或低功耗環境運行更大模型;更高的速度則讓即時應用(如對話、翻譯、工具呼叫)變得真正「即時」。
這是硬體與軟體完美協同的典範——LPU 提供確定性舞台,編譯器與 Dynamic Sparse Attention 則是導演,讓 Llama 3 等模型在更小硬體上展現更強大性能。未來的 AI 硬體生態系統,將是一個充滿競爭、互補與協作的複雜格局,共同推動人工智慧技術邁向更廣闊的未來。
Groq 的創新還在持續演進中。
相關專文



コメント