TurboQuant vs Groq LPU:軟硬雙劍,誰能真正終結記憶體牆?
AI 推理的最大痛點,從來不是算力不足,而是記憶體牆(Memory Wall)。
LLM 每生成一個 token,就必須把前面的 Key-Value Cache(KV Cache)全搬進記憶體。上下文一長,記憶體用量就爆炸式成長:128K 上下文下,一個使用者可能吃掉數十 GB GPU 記憶體,還伴隨動態排程、cache miss 導致的延遲抖動。
2026 年 3 月,Google Research 丟出TurboQuant 這顆軟體核彈;同一時期,Groq LPU 則用硬體革命在另一條戰線猛攻。這兩把「軟硬雙劍」,究竟誰能真正終結記憶體牆?還是它們其實是最佳拍檔?
1. TurboQuant:軟體極限壓縮,把 KV Cache 壓到只剩 1/6
Google Research 於 3 月 24 日發表 TurboQuant(將於 ICLR 2026 發表),這是一套無需訓練、資料無關的向量量化演算法,專攻 LLM 推理階段最吃記憶體的 KV Cache。
核心兩階段機制:
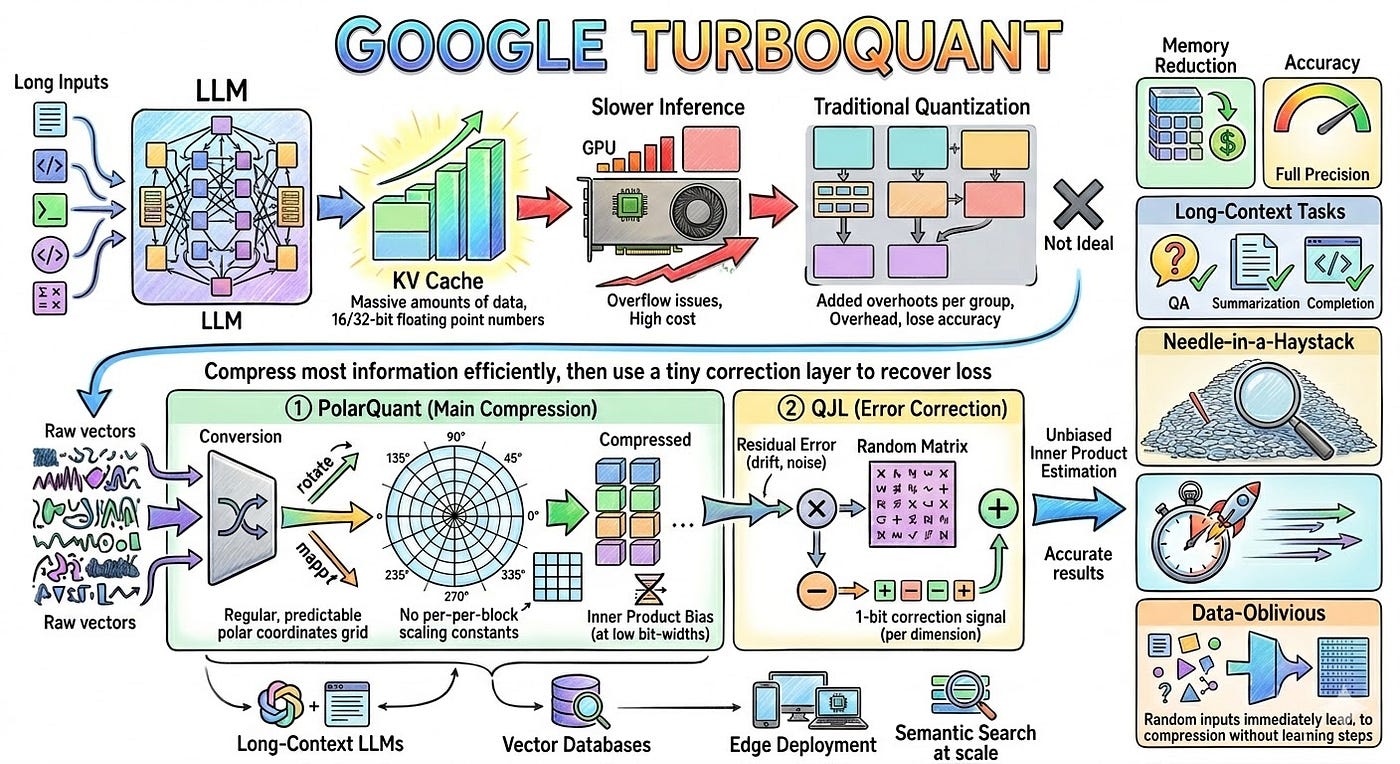

- PolarQuant:將向量從直角座標轉為極座標,讓角度分佈更集中,省去傳統量化常見的 per-block 正規化,減少偏差。
- Quantized Johnson-Lindenstrauss (QJL):再用 1-bit 投影修正剩餘誤差,確保 attention 計算的內積幾乎零失真。

實測成果(Gemma、Mistral、Llama-3.1 等模型):
- KV Cache 壓縮至 3~3.5 bit,記憶體用量減少 至少 6 倍(逾 83%)。
- 在 NVIDIA H100 上,4-bit TurboQuant 計算 attention logits 最高快 8 倍。
- Needle-in-a-Haystack、LongBench 等長上下文任務完全零精度損失。
這意味著:現有 GPU 不換硬體,就能立刻省下 80% 以上 KV Cache 記憶體,同一張卡能服務更多請求、支援更長上下文,推理成本大幅下降。
2. Groq LPU:硬體「可程式化輸送帶」,從根本消除等待
TurboQuant 是「把資料壓小」,Groq LPU 則是「從頭設計就不讓資料等記憶體」。
Groq LPU 的核心是 Software-First + Static Scheduling(靜態排程):


- 編譯時決定一切:Groq Compiler 把整個模型拆成精確的運算步驟與資料移動路徑,每個 clock cycle 都預先安排好。
- 運行時零動態:無 cache miss、無仲裁、無分支預測失敗,資料像精密輸送帶一樣穩定流動 → 確定性執行(Deterministic Execution)。
- 巨量片上 SRAM:單顆 LPU 內建高達 500 MB 高速 SRAM 作為主要儲存,內部頻寬高達 150 TB/s(遠超 H100 HBM),徹底繞過傳統記憶體牆。
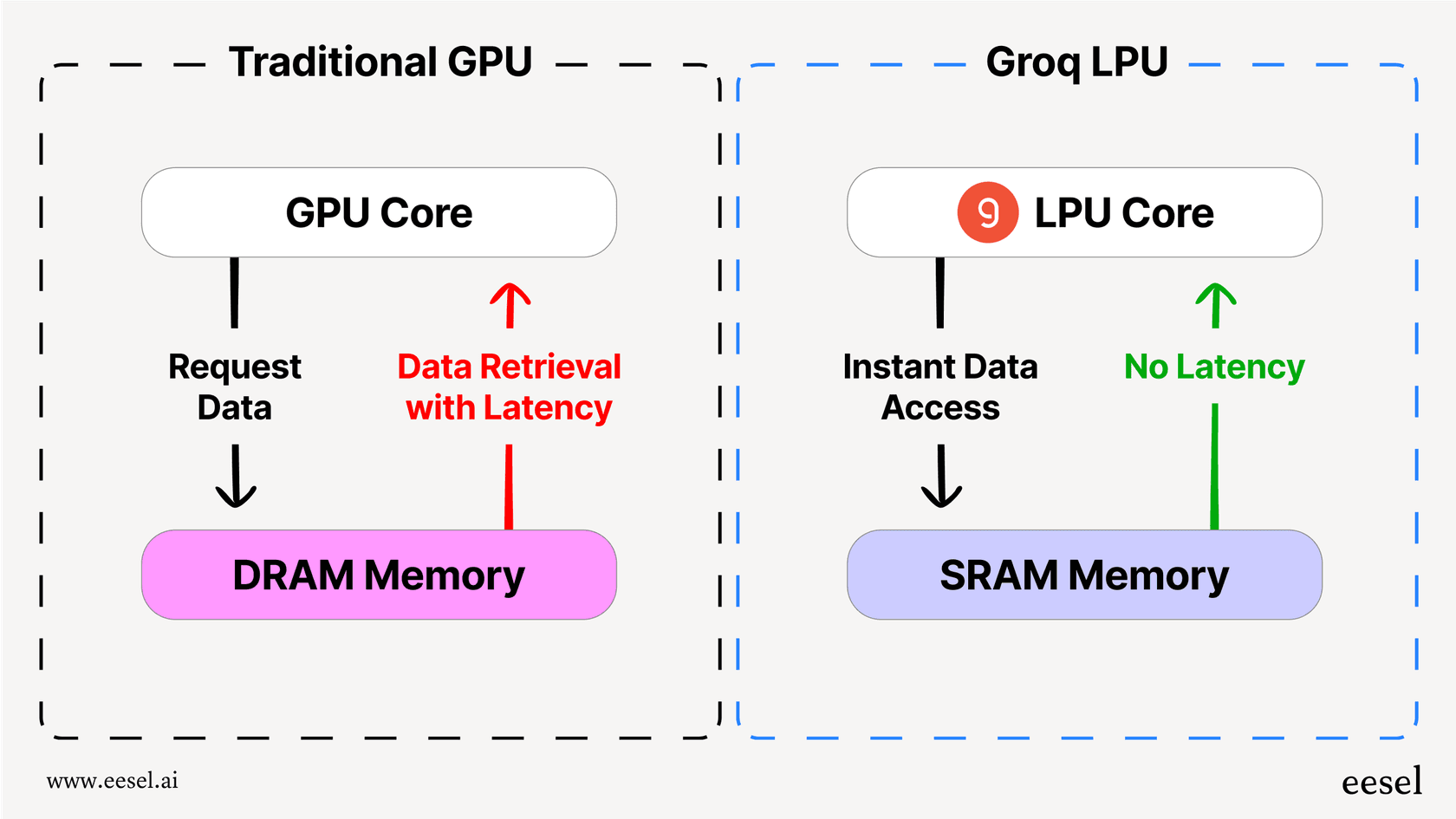
傳統 GPU vs Groq LPU 記憶體存取對比(左:動態等待;右:即時無延遲)
3. KV Cache 是記憶體牆的罪魁禍首

這兩張圖清楚顯示:在預填充(Prefill)階段,KV Cache 如何平行寫入並在解碼階段被重複讀取,導致記憶體用量隨上下文長度線性爆炸。
4. Groq LPU 的「輸送帶」概念
資料像工廠生產線一樣穩定流動,多顆 LPU 串聯就像一條更長的輸送帶,行為完全一致,無需複雜同步。
5. 軟硬對決表格
|
面向 |
TurboQuant(軟體劍) |
Groq LPU(硬體劍) |
誰勝? |
|
記憶體解決方式 |
極限壓縮 KV Cache(6x 省) |
片上巨量 SRAM + 零等待 |
平手 |
|
速度提升 |
Attention 計算最高 8x |
整體確定性低延遲(輸送帶式) |
TurboQuant 贏 attention;LPU 贏整體 |
|
穩定性 |
零精度損失 |
零 jitter,確定性執行 |
LPU 勝即時應用 |
|
部署難度 |
即插即用,現有硬體直接套 |
需要 Groq 專屬硬體與 Compiler |
TurboQuant 勝普及性 |
|
適用場景 |
高吞吐、雲端大規模 |
極低延遲、串流生成、即時對話 |
看需求 |
最佳未來形態:TurboQuant 壓縮後的 KV Cache + Groq LPU 的靜態輸送帶 → 記憶體極省、延遲極穩、成本極低,三贏!
6. 結論:傑文斯悖論再次發威
效率大幅提升後,原本因太貴而卡住的應用(超長上下文、個人化 Agent、多模態即時互動、邊緣推理)將全面引爆。AI 的「餅」只會越做越大。
沒有誰能單獨終結記憶體牆。
Groq LPU 帶來「硬體無限」:巨量片上 SRAM + 靜態輸送帶,不必等記憶體,重新定義什麼叫「效能」。
TurboQuant 讓現有硬體飛起來:把 KV Cache 壓到只剩 1/6,上下文感覺無限長
當兩者結合的那一天,就是 LLM 推理真正接近「記憶體無限」時代的開始。
2026 這場 AI 效率大解密,剛揭開序幕。
相關專文



コメント